Case study
Batch service & lifecycle visibility
The tension
Background jobs are where most production systems hide their failures. A cron runs, something throws, an exception lands in a log nobody reads, and the data drifts quietly. By the time anyone notices, the corruption is weeks deep.
Why the naive solution fails
The default pattern: schedule a job, log on failure, alert on exceptions. This works for one job. With thirty-five jobs running on different cadences, against the same shared dataset, with credit-accounted vendor calls in the middle, "check the logs" stops being an answer. Failures pile up below the noise floor and nobody sees them until something user-visible breaks.
The design rule
State tells the truth, not logs. The data itself records its own processing history. UpdatesStart and UpdatesEnd per data type per entity — three observable states:
UpdatesStart = null → never processed
UpdatesStart ≠ null, UpdatesEnd = null → in flight (or crashed mid-flight)
UpdatesStart ≠ null, UpdatesEnd ≠ null → completed; the value is the recency
The admin reads from this state directly. There is no separate monitoring layer that can drift out of sync with reality.
What was actually built
A coordinator above, executors below.
BatchCoordinator owns the schedule, picks the next batch, runs retry, throttling, and credit accounting. It never knows what a specific batch does. JobExecutor.HasCredits defers a job when the minute-level vendor quota is exhausted (the same hook used by the TwelveData boundary).
35 executors handle the actual work: stock import, daily and intraday price ingestion, financial statement ingestion, dividend tracking, observation computation, interpretation resolution, AI content generation, cache warming. Each one knows one job and writes its own UpdatesStart / UpdatesEnd per entity. Each one is idempotent: re-running a half-finished batch picks up where it left off.
Three properties fall out of this design:
- Recovery is automatic. A reboot mid-batch leaves half-processed records with
UpdatesStartand noUpdatesEnd. The next coordinator tick finds them and queues them again. - Prioritization is correct by default. The coordinator sorts by oldest
UpdatesEndand works the top. New stocks, stale data, recovered failures — all rise to the surface without queue management. - Cost is bounded. Credit accounting at the call level (not per batch) means throttling decisions are made on real numbers.
Evidence
The admin reads the same state the executors write. No drift, no separate monitoring layer.
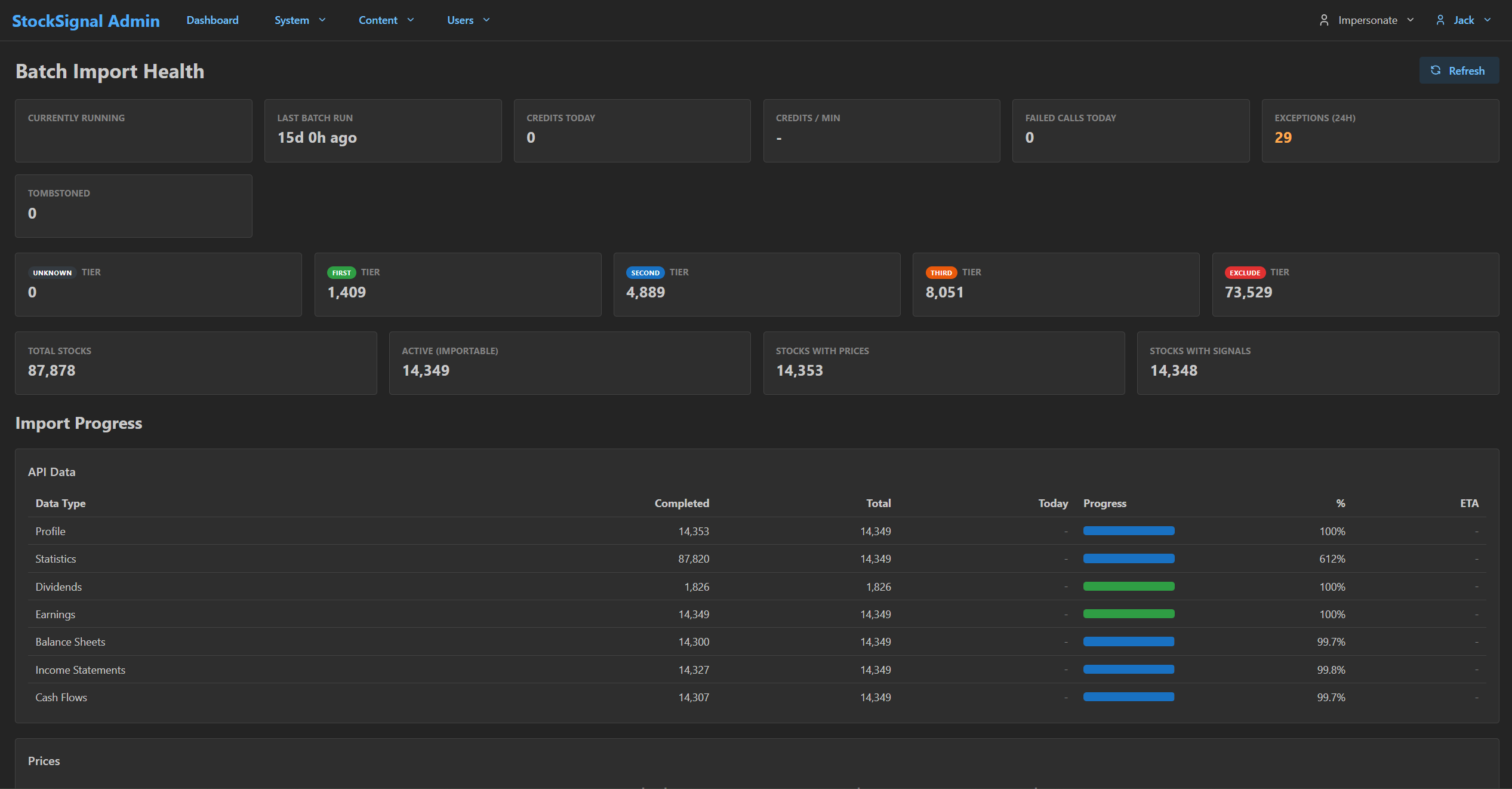
29 currently running, 29 exceptions in 24 hours, tier breakdown across 87,878 stocks (First 1,409 / Second 4,889 / Third 8,051 / Exclude 73,529), per-data-type completion progress. This is one query against the same UpdatesStart/UpdatesEnd columns the executors write — not a monitoring system.
Failures are queryable, not buried.
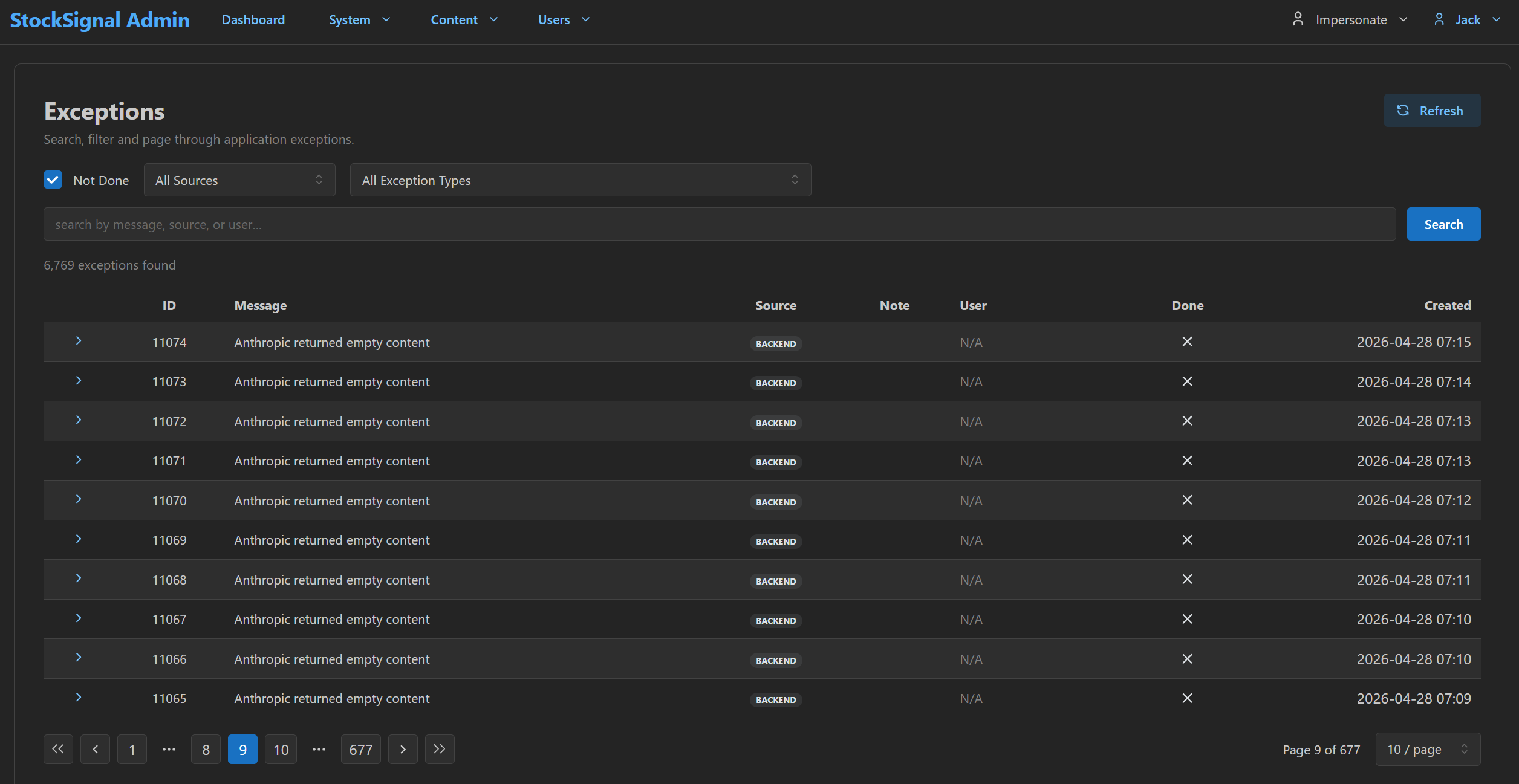
6,769 exceptions found, with a Done/Not-Done filter so the operator can triage instead of re-reading the same noise. The pressure to "investigate that weird thing" never accumulates because the weird thing is on the page.
What this proves Smallbox can do
Build background pipelines an operator can actually run — recovery is automatic, prioritization is correct by default, cost is bounded, and failures don't hide.
Want your product in this shape?