Method · Orientation, not oracle
The map is not the terrain.
This page shows how we work alongside an AI coding agent without letting its memory become the source of truth: the rule itself, a clean verification on a multi-subsystem log surface, a live drift caught on 28 May 2026, and the gate that keeps the map and the running system aligned.
The expensive mistakes in inherited systems are rarely about wrong code. They are about old maps treated as current truth — a README pointing at an endpoint that has since moved, a memory of a flag that was renamed last quarter, a deploy log that reads complete while the artifact on disk is yesterday's. Each stale source still looks authoritative. An AI agent reading the same codebase amplifies the pattern: it produces confident inference against a map the world no longer matches. The principle below — and the live drift that follows — is the discipline we use to keep the gap between map and terrain visible, whenever a system is too large to hold in any single head.
The rule.
An AI agent working on a long-running codebase has two inputs that age silently: the project files it has indexed inside the current session, and the durable memory it carries across sessions. Both are written at one point in time. The running code moves. So the first line of doctrine in our project file is not about style or architecture — it is about which of those signals is allowed to settle a question.
# CLAUDE.md — Doctrine, first principle
### Orientation, not oracle — verify before answering
This file and memory are an orientation layer, not the answer.
They route you to where to look; they don't replace looking.
Code wins over CLAUDE.md wins over memory — both age between
sessions; the code is what shipped. For any non-trivial question
— especially "what does X do today", "does Y still exist",
"what's the current state of Z", "where is this owned" — start
by reading the code, grepping the symbol, opening the file, or
hitting prod. Do not recite the map.The point is small and load-bearing. Memory routes; code answers. A claim that a function exists, a flag is set, an endpoint is mounted, or an entity is owned by service X is a claim about a moment, not a fact. Verifying it costs one grep. Skipping the grep is the failure mode this rule is here to prevent.
Kept: a multi-subsystem surface, verifiable at a glance.
The CompanyGraph admin has one page that aggregates startup heartbeats and intentional log lines from every running subsystem. Each subsystem identifies itself by its real name and carries a stable colour so a human reader can scan and a reviewer can verify that what is supposed to be running is actually running — and that nothing is missing.
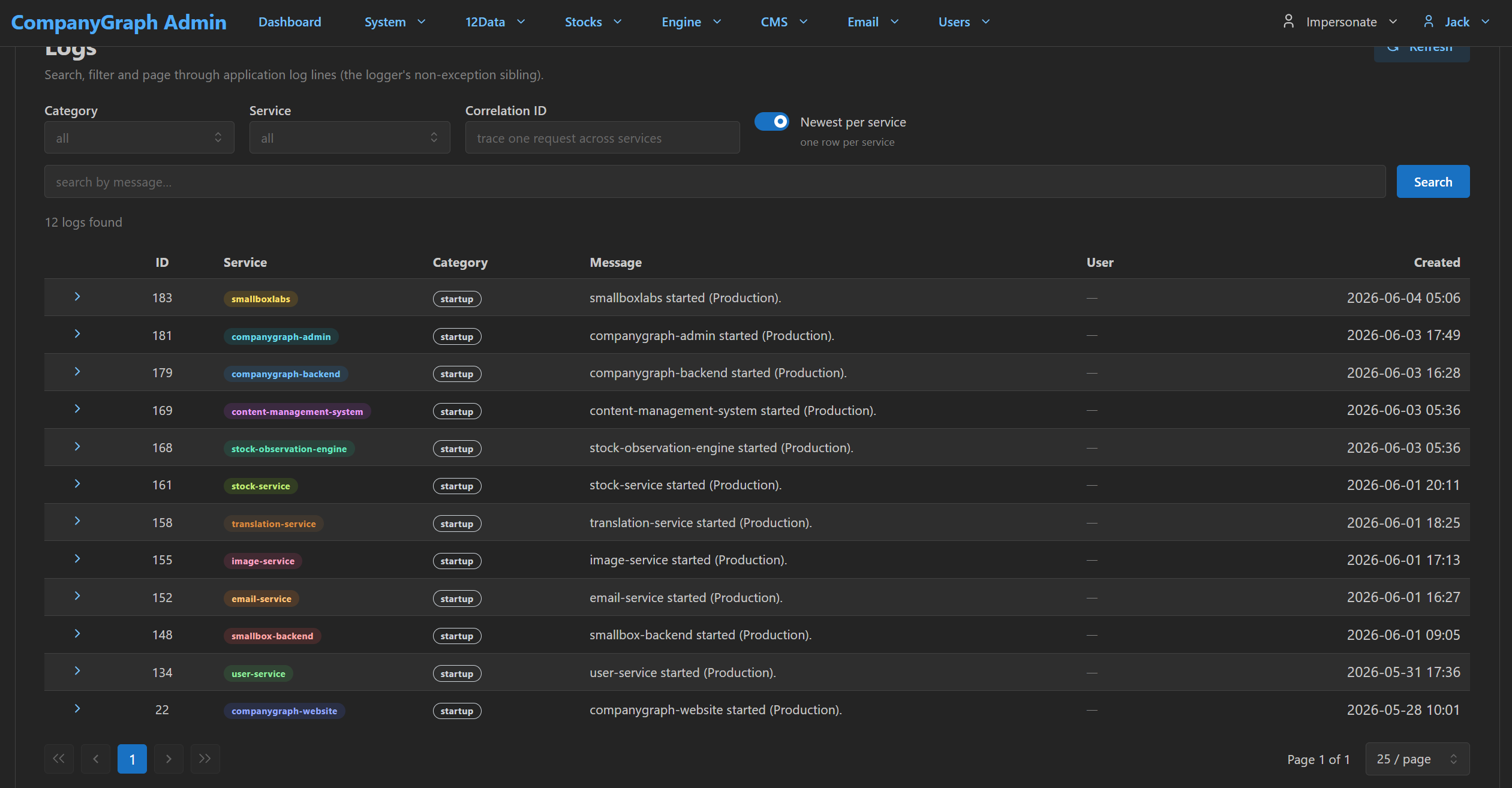
Category = startup with the Newest per service toggle on. Twelve services each emit one row when they boot — the CompanyGraph backend, admin, and website; the engine, CMS, and the image, email, stock, translation, and user services; and the Smallbox Labs site and backend. The logger sits beside them.What this surface buys is not aesthetic. Three properties hold.
- The map is checkable. If the agent claims a subsystem is live, this page proves or disproves it in one look. If the screenshot is missing a row, the agent's map is wrong.
- The names are honest. Each row uses the subsystem's full identifier —
stock-observation-engine, notengine;content-management-system, notcms. Short names hide drift. Full names force the question. - The colours are stable. Same subsystem, same colour, every session. A reader builds a visual habit and notices the absence of a colour they expected to see — a stronger signal than reading any list.
This is the cheap end of the loop. Open the page, confirm the world matches the map, continue. When the page disagrees with the map, the map is wrong.
Drift: a deploy that “succeeded” and shipped nothing.
On 28 May 2026 we added a small feature to the admin Logs page: a switch that collapses the result list to one row per service. It is a thin change across three repositories — a property on the logger's SDK request, a query change in the logger, a flag forwarded by the backend proxy, a switch on the admin. All four built locally. All four were pushed and deployed in the right order: SDK-owning service first, backend second, admin last. Every deploy log read Deploy complete.
The toggle, when reloaded in production, did nothing. The list stayed the same.
The honest read of that moment was: the map and the terrain disagree. Memory said the change was deployed. Three green build logs said the change was deployed. The system said the change was deployed. The page said it was not. So we stopped reasoning from memory and looked at the running system.
$ ssh prod 'ls -la /opt/companygraph/backend/publish/api/Smallbox.Logging.dll \
/opt/logger-service/Smallbox.Logging/bin/Release/net9.0/Smallbox.Logging.dll'
-rw-r--r-- 32768 May 27 16:17 backend/publish/api/Smallbox.Logging.dll # what backend serves
-rw-r--r-- 32768 May 28 09:38 logger-service/.../Smallbox.Logging.dll # what was just shippedThe backend was serving an SDK DLL from the previous day, even though its HEAD pointed at today's commit and its build log read clean. The cause was a subtle one: the backend's deploy script clears its sibling SDK build cache only when that sibling's HEAD changed during this deploy. The logger-service had already advanced HEAD on its own deploy moments earlier, so by the time the backend deploy ran, the sibling check saw before == after and skipped the clear. MSBuild's incremental-build cache then happily reused yesterday's SDK DLL inside the backend's publish output. No build error. No 502. The new property was simply not in the deployed binary, so the inbound query parameter silently bound to the type default. The toggle did nothing because there was nothing to toggle.
No amount of re-reading the doctrine would have caught this. No re-reading of the source would have caught this. Only one signal exposed the gap — the timestamps of two files on the production filesystem. The map said it was deployed. The terrain said it was not. The terrain wins.
Gate: what catches drift, and what doesn't.
The rule by itself is a posture. The posture has to be supported by something the system actually does. The doctrine file ends with the maintenance loop:
# CLAUDE.md — Keeping the map honest
Same-commit rule. A change that moves a boundary, ships a phase,
or alters a user-facing rule updates the matching LIVING doc
in the same commit.
A code change that flips a default, renames a config key, moves
a boundary, or changes a product rule must revise any index /
Current-state line it falsifies, in that same commit.
Replay. Take the last ~30 commits + open BACKLOG items + a
session's real asks, and for each — with only this file loaded —
check that a trigger matches and routes to the right answer.
Every miss is a missing trigger or a stale answer; fix it and
re-run.- What it catches today. Boundary moves, renamed config keys, flipped defaults, changed product rules, ownership shifts — the kinds of changes that quietly make a doctrine line false. The same-commit rule keeps the always-loaded always-true. The replay test sweeps recent commits against the trigger index and surfaces missing entries before the next session reads them.
- What it does not catch yet. A deploy that succeeds at the script level but ships a stale dependency — the exact shape of the drift above. The deploy script has been hardened (the backend now clears its own build cache before publish; the trap is documented in memory and in the deploy trigger), but the gate that would catch this class generically — a post-deploy timestamp diff between published artifacts and their source — does not yet exist. Until it does, the only thing protecting us is the discipline of looking at the running system before declaring a feature live.
The gate is honest about its own coverage. It refuses what it knows how to refuse and is openly silent about the rest. The next iteration adds a post-swap artifact-mtime check to the deploy script. Until that lands, the rule against trusting the deploy log is a rule the deploy pipeline does not yet fully back.
Why a live drift, not a clean example.
The drift in the previous section happened during this session. The fix shipped. The post-deploy gate that would catch it generically is not in yet. We could have built the gate, waited a week, and then written this page. We didn't. The published version of this method is one commit behind its own full coverage, and the page says so.
A synthesised clean example would have proven less. The principle here is not “our discipline is flawless.” The principle is that the discipline is checkable, and when it leaks — and it does — the leak goes onto the page next to the rule, not into a folder marked “known issues.”
The same loop applies on every project. Map for orientation. Code, database, logs, deployed binaries, timestamps for evidence. When the two disagree, widen the search and trust the terrain. When the map has been wrong for a reason that will recur, change the map in the same commit that changes the code.
The point is not perfect memory. The point is a system that makes its own drift visible.
This is how we'd work on an inherited system too.
The same instinct that compares two file timestamps to break the tie between “deploy complete” and “the feature is live” is the instinct we bring to a backend you have inherited — not as a posture about AI, but as a working method for telling claims from facts when the codebase is too large to hold in any single head.